
Hello, World3

Ryan S. Jeffery is an artist, researcher, professor and filmmaker.
Part I: A Computer Curve of Doom
On March 2, 1972, a global report hit bookstores in paperback. At just over two hundred pages, the modest ambition of its authors was nothing short of “a Copernican change of vision” for all of humanity. The news: the planet’s carrying capacity was reaching its limit. Global societal collapse was inevitable unless population growth, industrial activity, and resource consumption were all radically curbed. The authors telegraphed their Malthusian prescription in the title: The Limits to Growth. A publicity sensation, it sold over eight million copies worldwide and was translated into nearly thirty languages.
Behind the report was a large cohort of scientists, business leaders, and politicians known as the Club of Rome, named after the location of their first public meeting. Limits was a political lightning rod. It scrambled ideological lines over resource distribution, environmental conservation, and development across the global south, with accusations of austerity, denialism, Luddism, and political unfreedom flung in all directions. But a smaller part of the debate concerned the rise of computer power, its capacity to capture and describe the world, and how the technology itself might alter the world it purported to objectively describe.
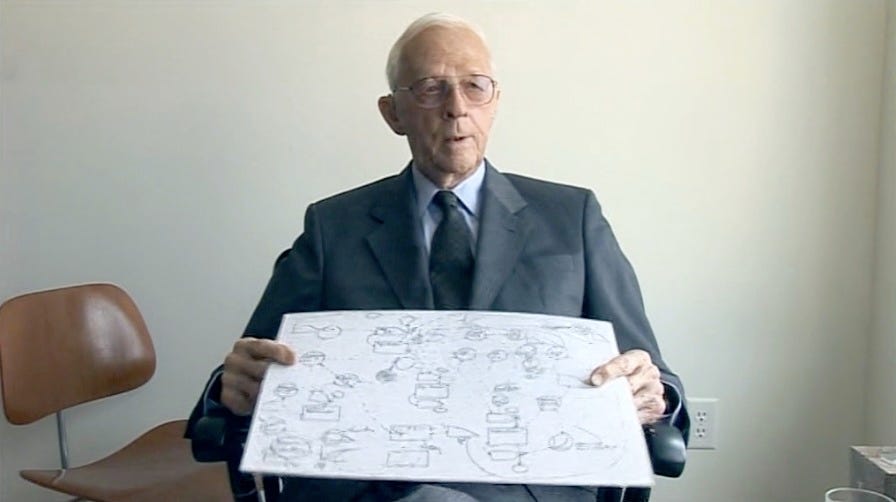
April 22, 1970, marked the first Earth Day, coinciding with the US government’s creation of the Environmental Protection Agency. Global environmental degradation seemed to be at a tipping point. To meet the complexity of the challenge, the Club of Rome turned to Jay Forrester, a leading figure in computer engineering and systems theory. Forrester helped develop magnetic core memory and is even co-credited with generating the first computer animation (a bouncing ball on an oscilloscope). Like most of his generation, he took part in the war effort and helped design cybernetic systems for gun turrets and radar antennae. After the war, he went to MIT’s Sloan School of Management, where he developed what he termed “system dynamics” to model and refine enterprise logistics for factories, and then entire cities. With The Club of Rome, Forrester would tackle the most dynamic system yet—the world. Filmmaker Adam Curtis vividly reconstructs the events of this encounter in the series All Watched Over by Machines of Loving Grace, with Forrester himself describing his dynamic model of the world direct-to-camera.

Using Forrester’s methods, a team at MIT made multiple versions of the world. They arrived at World3 for the 1972 report. This was widely considered the start of the field of global modeling. But amid the various critics of Forrester and his “computer curve to doomsday,” some of the fiercest were themselves technologists. Horrified by what they perceived as a dangerous kneecapping of progress, a younger cohort of engineers defined themselves in direct opposition to Limits as they championed the virtues of entrepreneurship, free-market economics, and, crucially, resource abundance. Historian Patrick McCray argues that what set this new breed of public-facing technologist apart was the clarity of their shared vision for the future. These Visioneers, as McCray calls them, were emphatic about a utopian horizon that hinged on two technological achievements at polar opposite scales: nanotechnology and the human colonization of space. If none of this summons today’s image-conscious tech titans hawking relentless amazingness, consider their latest pitch: orbital data centers.
Part II: World Does Not Compute
Ultimately, the forces of growth prevailed over the warnings of Limits, yet the idea of global (or world) modeling carried on. Only today, it’s firmly in the hands of those bullish on growth at all costs. It’s been nearly four years since the arrival of large language models (LLMs), and their sparkle might be dimming. Anxieties over mass layoffs and anti-data center populism are bipartisan. Talk of scaling walls and hallucinations persistently drag, while the specter of bubbles, overbuild, and the ever-elusive productivity gain haunt the financial pages. Are fewer feeling the AGI?
Perhaps a pivot is nigh. Quinn Slobodian and Ben Tarnoff have done the work to remind us that when Musk moves, we still need to take notice, whether we want to or not. Last fall, the richest man in the world announced he was throwing his hat in the race for world models. Indeed, the audacity of the name alone is already on brand. But the starting gun may have been fired by Yann LeCun, who, until recently, was the chief scientist leading Meta’s AI laboratory. LeCun turned heads last fall when he expressed doubts over the limits of LLMs and left to start his own company devoted to world models. He has all the right credentials to make his break with current industry convention so seductive for the financial press. He is a recipient of the prestigious Turing award, which he shares with Geoffrey Hinton, the reputed “godfather of AI,” and with whom LeCun also studied. Having already raised $1 Billion, the brash Frenchman has played the media meme game impeccably, teeing up juicy pull quotes like “AI sucks.” (He’s also a big jazz head.)


So what are world models, and how do they differ from LLMs? In the simplest terms, LLMs are designed to detect statistical patterns in human language and predict the probability of the next word (token), given all the previous words (tokens). This is why many detractors often dismiss the technology as glorified auto-complete. The advent of multimodal models (MLLMs) gave way to video and image generators that can map relationships between different types, or modalities, of data. Proponents of world models argue that, as impressive as these technologies are, they cannot provide an actual causal law of the physical world.
The word causal is important to world model boosters. The objective is a computer’s embodied perception of the world, down to the laws of physics. It’s the long-awaited promise to bridge the computer world of bits with the physical world of atoms. Tea, earl grey. Hot! For world model advocates like Fei-Fei Li of ImageNet fame, the linguistic construct of LLM architecture keeps them “wordsmiths in the dark,” to use her words. In a well-known Substack post that got many in Silicon Valley name-dropping Wittgenstein, Li spelled it out, “From Words to Worlds: Spatial Intelligence is AI’s Next Frontier.” Where LLMs describe, world models might act. In a sense, this emphasis between language and embodiment harkens back to an online typology that surfaced a few years ago, which sorted human intelligence into two archetypes: wordcels and shapeorators. In the parlance of the meme: LLMs are wordcels, world models are shape rotators.

The concept of world models is credited to computer scientists David Ha and Jürgen Schmidhuber. They wanted to overcome limitations they saw in reinforcement learning, a core principle of machine learning concerned with how an AI agent takes actions in dynamic situations. Their idea was to train a computer by mimicking how they understood humans learned about the world, by running a smaller, abstracted mental model of it within one’s own mind. In technical lingo, this means using neural networks to “compress spatiotemporal representations and simulate common reinforcement learning environments.” But Ha and Schmidhuber also put it more poetically, describing how an agent can be trained “entirely inside of its own hallucinated dream generated by its world model.” Dreams are a go-to metaphor for advocates of world models. In another popular tech and business Substack post titled “World Models: Computing the Uncomputable” by entrepreneur Packy McCormick, he explains world models through the analogy of lucid dreaming, drawing from Ha and Schmidhuber, along with a host of other thinkers on the nature of reality that range from Plato to Phillip K. Dick, and the Daoist philosopher Zhuangzi. Ha and Schmidhuber are less overtly philosophical in their paper. They begin by breaking down several common human activities: driving a car, hitting a baseball, and, of course, gaming. But the goal is no less ambitious, if not audacious: to imbue computers with experience and instinct. The anticipation of a glass of water falling when set too close to the edge of a table, the idea is for a computer to do that. The approach breaks down into three tenets: action, causality, and, most crucially, non-deterministic computing, what we might call counterfactual reasoning.
Fei-Fei Li expands on this:
“As spatially intelligent world models become more powerful and robust in their reasoning and generation capabilities, it is conceivable that in the case of a given goal, the world models themselves would be able to predict not only the next state of the world, but also the next actions based on the new state.”
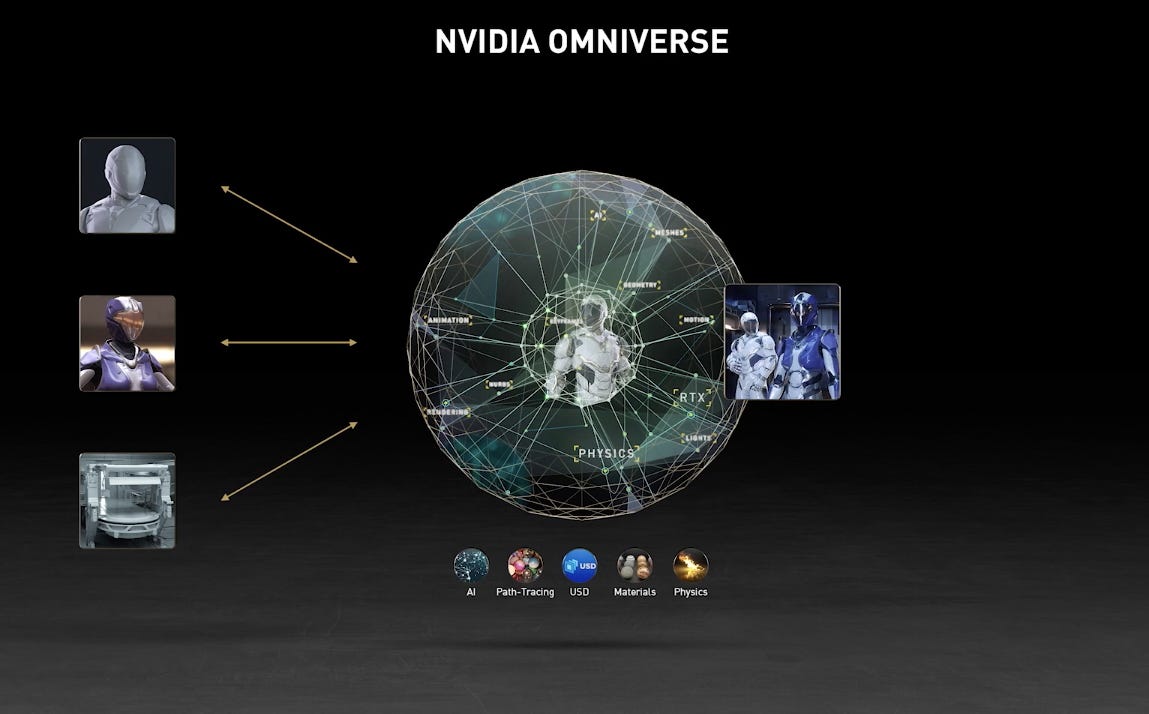
Currently, AI agents are primarily confined to software; their training models are task-specific, as opposed to a unified model of action and space. World models carry a promise that so-called agentic AI might escape the confines of software and join the physical world through hardware, for, as one computer scientist reminds: “While there can be many tasks and policies, there is only one world in which we live that is governed by the same set of physical laws.” This is a quest for “physical AI,” i.e., robots. To return to Musk, his interest in world models falls into sharper relief when taking into account his long-unfulfilled promise of mass-produced humanoid robots. Musk entered the arena of world models the only way he knows how—aggressively. He kicked it off on a hiring spree, courting high-profile researchers from NVIDIA, and announced “a great AI-generated game” coming sometime this year. As always, it runs through gaming. NVIDIA, whose success originates in the gaming industry, has been in on world models from the get-go and markets what it calls Omniverse: a simulated digital twin of the world for “trial and error reinforcement learning AI feedback.” This is essentially Ha and Schmidhuber’s hallucinated dream for androids to train inside before they’re deployed to take over assembly lines and be our butlers. World models mean a job training center for robots and an escape into the holodeck for you and me.

PART III: A Myth of Total Slop
The application for world modeling appears to be moving in three general directions: robotics, gaming, and film. Reading over the mission statements and audacious proclamations across the various world model endeavors, one would likely never know that the concept originated from Jay Forrestor’s dynamic systems. Ha and Schmiderhuber cite Forrester in the introduction of their original paper: “The image of the world around us, which we carry in our head, is just a model. Nobody in his head imagines all the world, government or country. He has only selected concepts, and relationships between them, and uses those to represent the real system.” Hardly a trace of this humility, much less a concern for limits, can be found amid the breakneck pace of capital accumulation and carnival barking in the race for the next frontier. Confusion and vague overpromising are to be expected. But this isn’t the first time anyone has dared to claim that the map could be the territory.
For film theorist Andre Bazin, it was the technology of cinema. Writing in 1946, Bazin argued in “The Myth of Total Cinema” that the technological achievements of the moving image could at last close the gap in the longstanding irrational drive for the total recreation of the world. The myth of recreating reality would no longer remain one. By his calculation, totality would arrive by the year 2000. According to the film critic J. Hoberman, Bazin was only off by about a decade. The catch: the myth no longer needed the world. “Digital image-making,” Hoberman wrote in 2012, “precludes the necessity of having the world, or even a really existing subject, before the camera—let alone the need for a camera.” The profilmic event—the subject being filmed, i.e., material reality—no longer seemed necessary. In 1877, Eadweard Muybridge aimed a lens (twelve, actually) at a galloping horse and captured the light that reflected off this action, which then fixed a pattern of silver nitrate onto an emulsion to represent motion in the world. A century and a half later, a real galloping horse is no longer necessary to capture this motion. Instead, billions of transistors on a microchip perform a dizzying number of seemingly instantaneous calculations to arrange a pattern of pixels that simulate a horse galloping. Media theorist Lev Manovich has been developing a taxonomy to make sense of this new landscape, from analog to digital to algorithmic. And yet, to the extent the horse’s earthly presence is no longer required to render an impression of its motion, the earth’s minerals and resources are still needed to power the simulation. Hard as they may try, images can never completely disavow the material world.


When everything’s computer, it’s often difficult to know whether a committed idea was really ever in the works, or if it’s just improvised short-termism all the way down. If the goal for OpenAI’s Sora was the latter, then it’s far easier to tout its success. The first peek into Sora’s trademark-infringing uncanny valley came in 2024, but OpenAI had to pull something else from their sleeve the following year, after the “we’re cooked!” sensation of Google’s Veo 3. Sora 2 was the response, dropped in a social-media styled wrapper in the vein of TikTok. Bazin’s Total Cinema arrived as a nightmare of total slop. Most of the talk centered around the all-too-familiar vapid game-engine aesthetics, its blatant disregard for IP, and puzzlement over the social media angle. But in computer engineering circles, there was genuine admiration for the model’s unparalleled fidelity to the physics of material reality, no matter how surreal or fantastical the prompt. It gestured towards the central conceit of world models: a spatially grounded facsimile of the world, whether real or virtual. This is what’s implied when world model advocates say causal and predictive, not just predicting the next pixel in a video image, but the next state of the world. In the case of Sora, the result was that physical objects appeared to behave in accordance with the laws of physics, including the optics of the image itself. If the camera perspective moved, then the light also shifted as if it were actually captured by photons bouncing through a camera’s lens—only it wasn’t.
OpenAI was not shy about calling Sora (now cancelled) a world simulator, even if it was still a generative video model. This comes as little surprise, given the company’s thirst for hype, but it also speaks to just how nascent the world model space is. Terms like world modeling, world simulator, and digital twins are tossed around interchangeably, with the expected hairsplitting over which qualifies as which. The most agreed-upon definition of world models is an environment that an agent can act in and respond to in real time, thus a world model is “action-conditioned.” By this definition, it’s clear that Sora was a video model, not a world model, since it only predicted a pixel world that one passively observed. But the lines are blurry and getting blurrier. At this point, there are more than a half dozen purported video-based world models/simulators, including one named Odyssey, “a world simulator that dreams in video,” allowing you to prompt the video mid-stream to take it in whichever direction you wish.


Just before his death over a decade ago, the German filmmaker Harun Farocki could already see the decline of the cinematographic image in favor of the computer-generated image. “The era of reproduction seems to be over,” he remarked. “A construction of a new world seems to be already here.” Farocki’s profoundly influential concept of the operational image has been instrumental to thinking through image production in the algorithmic age. Yet the promises of world models (if they are to be believed) seem poised to scramble the relationship between visuality and computation even further, with proprietary mathematical abstraction on one hand, and immersive, virtually generated futures and worlds on the other.
Over half a century ago, Jay Forrester’s World3 arrived with a warning about the Earth’s limits. Today, private companies with market caps larger than most countries are working to shrink the world to fit inside a computer. For firms like NVIDIA and Google, there seem to be no limits. NASA’s Earth System and the European Union’s Destination Earth offer some public-sector participation with an eye towards climate instability, if not collapse, and still, whether to monitor its climate or marshal its resources, twinning the Earth largely remains in the hands of private actors. Writing on the history of planetary science and scale, scholars Orit Halpern, Robert Mitchell, and Henning Schmidgen argue: “Digital twins of the earth presume that human policy expertise can neither grasp the enormous volume of information generated by global natural systems such as weather nor adjust policy at the necessary speed.” The question for Halpern, Mitchell, and Schmidgen appears to lead back to the question over (technospheric) governance that the Club of Rome encountered in 1972. Namely, who is “the we in the name of which these systems act,” and what are the “polities and powers that will emerge from such a project”?
Just like Yann LeCun, Fei-Fei Li also has a world model startup in this increasingly crowded market. Li’s firm is named World Labs. Their flagship model allows users to turn photos, videos, and 3D layouts into immersive virtual worlds. It’s called Marble, a likely nod to the famous “Blue Marble” photograph taken by astronaut Harrison Schmitt on the Apollo 17 mission in 1972, the same year that The Limits to Growth was published. In April of this year, astronaut Reid Wiseman of the Artemis II mission looked through the viewfinder of a Nikon 5D from the Orion spacecraft and snapped another photo of the Earth. No human had taken a photograph of the complete Earth disk since Schmitt, 54 years earlier. The photo was named “Hello, World,” a reference to a simple script commonly used in computer programming. It’s anyone’s guess which neural net gobbled it up first.

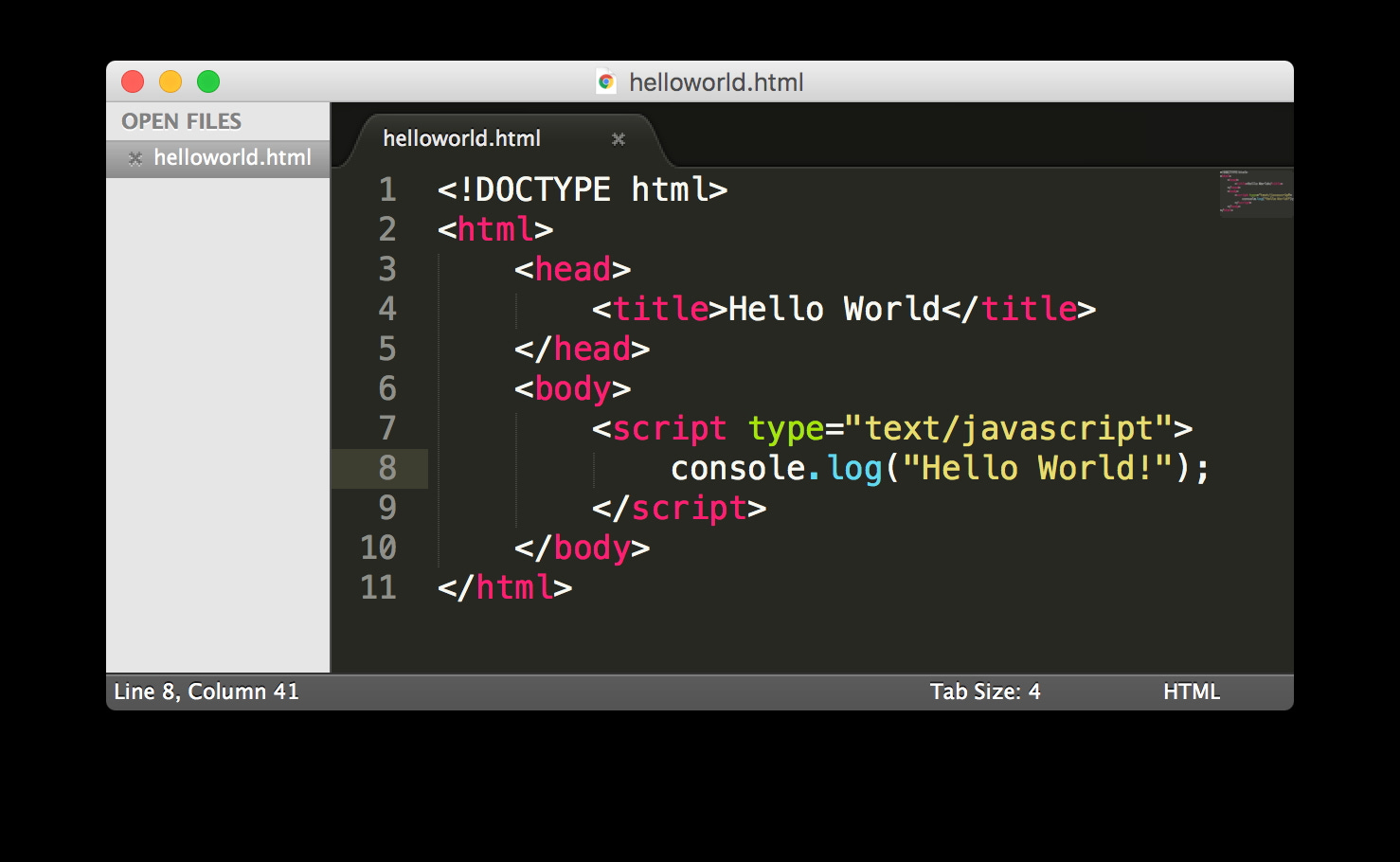
here’s a question for the world modelers: can the world models world model themselves? if they can, how? if they can’t, then there exists that which can’t be modeled